はじめに
医書.jpは医学書の電子書籍販売を行っているサイトです
めっちゃパソコン詳しい知人が医書.jpのセキュリティガバガバ過ぎてハッキングに成功したので手法をまとめてみました
手順
手順は大きく2つです
- 医書.jpのアンドロイドアプリからPDFを抽出する
- PDFのパスワードを解析して解除する
医書.jpのアンドロイドアプリからPDFを抽出する
医書.jpの電子書籍はアプリで読むタイプとwebで読むタイプの2種類あります
アプリで読むタイプは
- アプリ内にPDFファイルをダウンロード
- ダウンロードしたPDFファイルをアプリの専用ビュワーに表示
という仕組みです。つまり、アプリにダウンロードされたPDFファイルを見つけだせばなんとかなりそうですね。
手順
- アプリの用意
- アンドロイドのroot化
アプリの用意
医書.jpのアプリはアンドロイド版とiPhone版があります。
後述しますが、iPhone版はセキリュティが厳しいので今回使うのはアンドロイド版です
今回は実機を使わず、BlueStackを使います。BlueStackはPC上に仮想スマホを起動するアンドロイドエミュレーターです。
BlueStackを起動したら医書.jpのアプリをダウンロードしましょう。
医書.jpをダウンロードしたら欲しい本を購入してください。
アンドロイドのroot化
アンドロイドのroot化を説明する前に、root化とは何か説明します
市販のスマホは機能が制限された状態で売られています。
ようは、素人がスマホの根幹に関わる設定ファイルいじった結果スマホがぶっ壊れたみたいな状況が起きないようにしてるんですね
root化とはその機能の制限を解除して、スマホ内のすべてのファイル、ディレクトリにアクセスできるようにすることです。OSの権限を取得するとも言います。
ちなみにiPhoneはこのroot化が難しいです。これがアンドロイド版を使った理由です。
今回はBluestackを使った仮想スマホなんで、実機のroot化とやり方が異なります。
root化したらAndoroidTerminalEmulaterをGooglePlayStoreから入れてsuperSUで権限を取得して、/data/data/jp.isho.contents_viewer/files/file_164544_4380_1を見つけたら設定>ファイルからPCに送れるようにsu cp /data/data/jp.isho.contents_viewer/files/file_164544_4380_1 /storage/emulated/0/ にコピーしてください。あとはPCにエクスポートして終わり。
どうやら医書jpは、PDFをfile_六ケタの数字_コンテンツID_コンテンツタイプの規則で命名しているようです
追記:adbコマンドというアンドロイドとPCのやり取りするためのコマンドを使うと一発でPCに送れるらしい。
PDF開こうとするとパスワード求められるから、パスワードの解析が次のテーマ
PDFのパスワードを解析して解除する
手順
- 医書jpのAPKを入れてデコンパイルする
- javaを読み解く
- パスワード生成プログラムを書く
医書jpのAPKを入れてデコンパイルする
医書jpのapkをPCに入れてjadexでデコンパイル、jadexはgit cloneで使ったらええ、jadexはオプションでguiあるから、gui使ったほうが便利
デコンパイル流れとしてはapk→dex→jar→class→javaになる。javaはVScodeとか好きなんでみるといい
apkはzipみたいに圧縮するための拡張子だから一旦展開してからjadexするとよし
dex→javaまでjadexでデコンパイルできる
javaを読み解く
javaはオブジェクト指向と呼ばれるプログラミング言語でオブジェクト指向とは抽象化→具体化の流れのことだ。設計図から実物を作るみたいなものだ。専門用語で設計図をクラス、実物をインスタンスという。設計図があれば実物をいくつでも作れるし、設計図を少し変えて組み合わせればいろんな種類の実物が作れるよね。オブジェクト指向はこういったメリットがある。あと分かりやすい。
デコンパイルされたjavaを読み解く、オブジェクト指向を理解しているとsorceファイルのmodel以下が機能単位を抽象化したものだときな臭く感じるよう
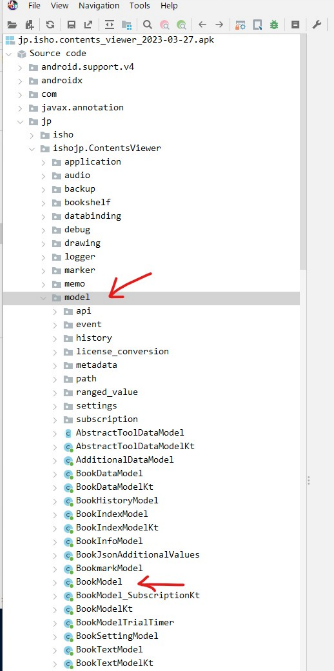
読みすすめるとjp.isho.ContentsViewer.model.BookDataModel.getPasswordByContents()でパスワードが生成されている事がわかる
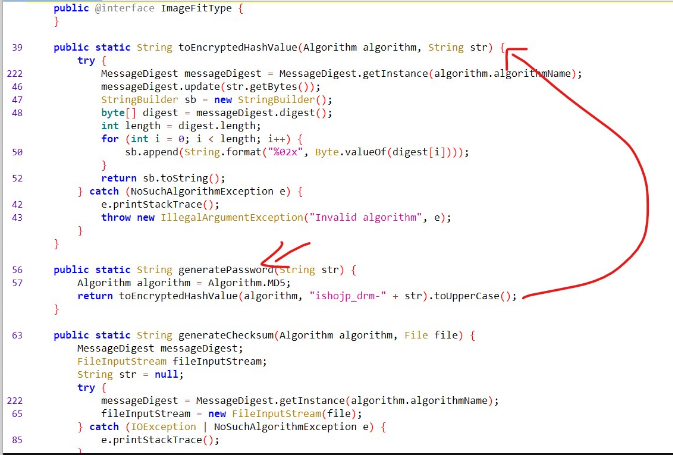
邪道だが、Passwordで検索してきな臭いメソッドを探し当てることもできる
パスワード生成プログラムを書く
コードの内容を簡単にいうとパスワードはContentsIDと特定の文字列を組み合わせてハッシュ化したものだ
医書jpのContentsIDはファイル名の2つ目の4ケタの数字となる。file_164544_4380_1なら4380だ。
ハッシュ化はデータを不規則な文字列に変えること。変換は不可逆的でセキュリティによく使われる方法だ。
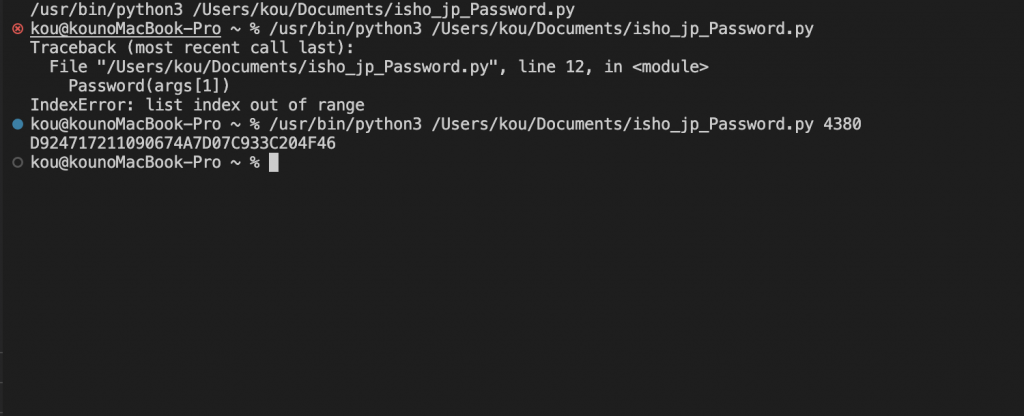
pythonで書くとこんな感じに↓
import hashlib
a = input("5桁の数字:")
def Password():
n = "ishojp_drm-" + a
hs = hashlib.md5(n.encode()).hexdigest().upper()
return print(hs)
Password()

コメント